Every ERP vendor now claims to be ‘AI-powered’—but which ones actually deliver?” Marketing hype, incomplete product documentation, and analyst reports often tell conflicting stories. Meanwhile, customers increasingly demand assurance that ERP vendors can deliver secure, cost-effective, and industry-relevant AI capabilities.
Most scoring models are built on checklists and expert opinion, making them rigid and manual. Without adapting to customer needs or current data, they lose relevance and credibility.
The question became: Could AI itself be used to improve ERP evaluations—without introducing more risk?
AI-Centric Model to Accelerate Selection
What began as a Proof of Concept has evolved into an AI-Centric evaluation model. We designed this model to answer this question, structured around three goals:
- Capture Customer Priorities – A Customer AI Requirements framework quantified what matters most, from AI transparency to deployment speed.
- Build a Weighted Scoring Model – Vendors were evaluated across 12 AI-related criteria (e.g., AI Capabilities, Governance, Integration Architecture, Industry-Specific AI). Customer-defined weights dynamically reshaped rankings in real time.
- Reduce Bias and Hallucinations – Vendor claims were cross-checked across multiple sources (vendor roadmaps, analyst reports, product documentations, community forums). AI-generated insights were only included if confirmed by at least one independent source.
Recipe for Success: It is important to weight source types as part of the AI-driven analysis. For example, community forums have a higher importance than product documentation.
In our case, the AI-driven model centered on evaluating ERP vendors’ AI capabilities and strategies. With AI now embedded in most ERP roadmaps, understanding vendor maturity, reliability, cost-effectiveness, and security posture is no longer optional — it’s essential.
The Approach
1. Multi-Model AI Research
We chose to utilize multiple AI chatbots. Our selection criteria was based on popularity that utilized different Large Language Models (LLMs). An LLM is like a giant “language calculator” — you give it words as input, and it calculates the most likely and useful words to give back.
| AI Chatbot | LLM (a.k.a “Brain”) |
| ChatGPT | GPT-5 (OpenAI) |
| Claude | Claude 3 (Anthropic) |
| Google Gemini | Gemini 1.5 (Google DeepMind) |
| MS Copilot | GPT-5 (via Azure OpenAI) |
| Perplexity AI | User-selectable: GPT-4, Claude 3, Mixtral, Command R |
2. Define High-Level AI Requirements
Customer requirements were mapped into 12 scoring categories, including:
- AI capabilities and scope (GenAI, ML, predictive analytics)
- AI governance and transparency (explainability, audit trails, usage monitoring)
- Deployment speed
- Cost efficiency
- Security and compliance
- Industry-specific AI readiness
- Integration architecture (native vs. hybrid vs. bolt-on)
3. Quantify Customer Priorities
The customer assigned weights (1–5) to each requirement. If multiple requirements mapped to the same criterion, we averaged the weights — preventing one area from being overweighted due to duplication.
4. Build the AI Model
We built a MS Excel spreadsheet to define the AI scoring model. Key attributes for the model:
- AI Chatbot
- Vendor Name
- Ranking
- Justification for Ranking
- Sources
5. Train the AI Chatbots
In order to promote consistent measures (apples to apples) across the AI chatbots, we educated each one on a clear and consistent definition for each requirement (criteria).
6. Score Vendors with AI-Assisted Research
Here’s where bias reduction came in:
- Multiple AI models (ChatGPT, Claude, Gemini, Copilot, Perplexity) were used to gather vendor insights.
- We avoided taking any AI output at face value — each claim was validated using independent analyst reports, customer forums, and vendor documentation.
- Scores were normalized to ensure consistent scaling across models.
7. Detect & Minimize AI Hallucinations
AI hallucinations (confident but false statements) are a real risk. We addressed this by:
- Using cross-model consensus: if only one AI tool claimed a capability, it was flagged for review.
- Requiring source citation for any vendor capability statement.
- Running an “interrogation” step where the AI was prompted to explain its reasoning — contradictions often revealed unreliable claims.



8. Apply Customer Weighting to Scores
We used Excel formulas to multiply each vendor’s criterion score by the customer’s weight, producing a Composite Weighted Score.
This method:
- Reflects exact customer priorities.
- Allows instant “what-if” analysis (e.g., “What if security is twice as important as cost?”).
9. visualize rankings in Pivot Tables
The AI-centric model was built with the following analysis.
- Overall ranking pivots based on the composite score.
- Per-criterion pivots for deep dives.
- Change-the-weight → Refresh → See new ranking in seconds.
Now, let’s bottom-line our efforts in the next section.
Results

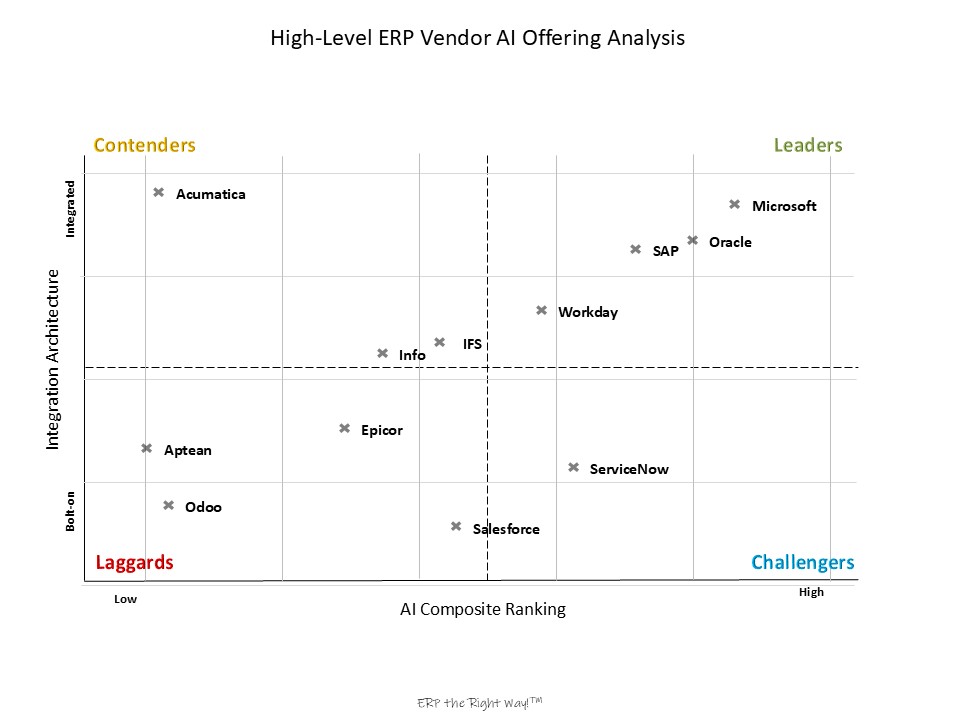
This illustration highlights vendors who deliver not only broad ERP coverage across all business areas but also embed AI natively, rather than relying on bolt-ons or hybrids. When applied to ERP vendors’ AI strategies, the model revealed clear insights:
- Customer Priorities Drive Rankings
Vendors rose or fell significantly depending on whether the customer weighted speed, security, or cost efficiency highest.
Example: Following is a standard market ranking with no customization prioritization versus a customer-specific ranking with a prioritization of how well the ERP vendor’s AI capabilities cover CX business process.

- Integration Architecture Differentiates Winners
Vendors relying on bolt-on AI dropped in ranking due to added complexity and cost. Native, embedded AI architectures scored higher. - Bias and Hallucination Reduction Worked
AI insights were only accepted when confirmed by at least one independent source. Discrepancies across tools flagged areas for manual review.
Together, this layered sourcing allowed the model to balance hype with reality. Vendor marketing was always checked against at least one independent or customer-sourced perspective, with AI outputs acting as accelerators — not final authorities.
Observations & Summary
Customer Weightings Matter: Rankings shifted noticeably once priorities were applied. Vendors strong in out-of-the-box AI rose when “Deployment Speed” and “Ease of Use” were weighted heavily. Vendors with strong governance and explainability ranked higher when “AI Security & Transparency” was emphasized.
Integration Architecture Was a Differentiator: Vendors relying on bolt-on AI ranked lower than those with native, embedded AI. This highlighted hidden complexity and costs.
Bias/Hallucination Minimization Worked: AI-generated insights were only used when confirmed by at least one independent or customer-sourced reference. Discrepancies across tools (ChatGPT, Claude, Gemini, etc.) flagged areas needing manual review.
Scoring Transparency Improved Trust: Because formulas tied directly to customer weightings and criteria, stakeholders could see why a vendor ranked higher or lower.
Value Propositions for AI-Centric Selections
- For Customers: A structured, bias-resistant framework to select ERP vendors based on real priorities.
- For Advisors: A repeatable method to guide ERP selections while reducing reliance on subjective vendor promises. For this AI-Centric model, we were able to reduce the initial effort from 2 weeks to 3 days!
- For Vendors: Clear visibility into what customers value most and where they lag behind competitors. Second, the results can be used to identify marketing gaps for their product features & services.
Best Practices for ERP AI Evaluation
- Start With Customer Priorities – Don’t let the vendor dictate what matters. Quantify the customer’s “must-haves” up front.
- Balance Human + AI Insight – Use AI to process scale and complexity, but validate against multiple sources to reduce hallucinations.
- Make It Transparent – Every ranking should be explainable. Show the math, show the sources.
- Account for Architecture – Integration design (native vs. bolt-on) often matters more than feature lists.
- Treat It as Iterative – Like ERP itself, evaluation models should evolve as customer needs and vendor offerings change.
Conclusion
The AI-Centric operational model proved that AI doesn’t replace ERP advisors—it enhances them. By embedding customer weightings into an AI-enabled evaluation model, we produced rankings that were more relevant, defensible, and resistant to bias than traditional approaches.
For ERP customers and advisors alike, this approach offers a new way forward: turning AI from a risk factor into a trusted partner in the decision-making process.

Leave a Reply